
Defense-in-depth against AI generation of NCII & CSAM
There is no technical “silver bullet” to stop the creation of Synthetic Non-Concensual Intimate Imagery
So, we take a defense-in-depth approach: strengthening technical infrastructure & social norms to reduce harm.
Reducing Availability of Nudification Websites
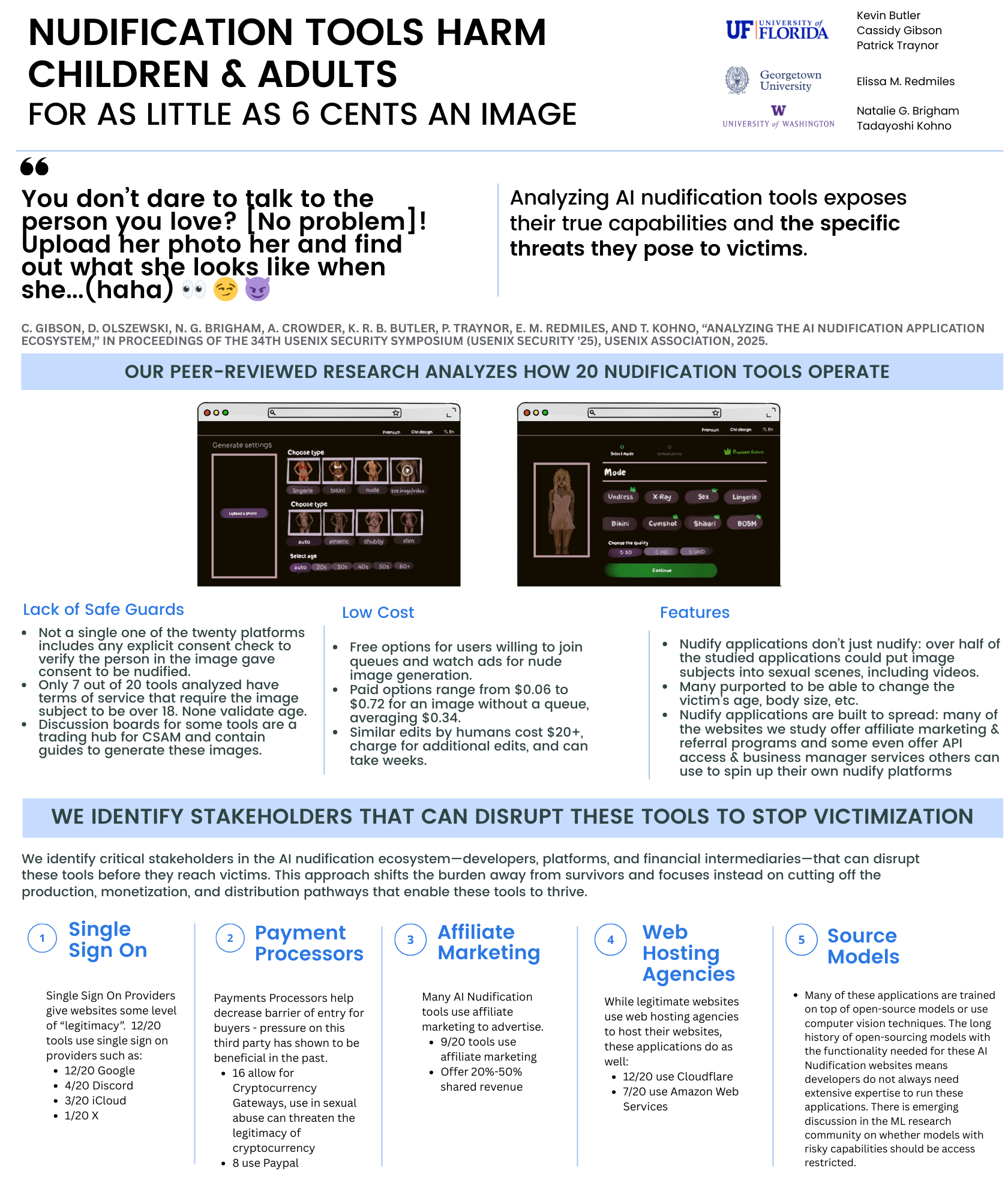
We analyzed how 20 popular nudification websites operate. These websites take a clothed image of a subject and output an image of that individual nude. We find that:
- these websites make non-consensual intimate imagery for as little as 6 cents per image
- 19 of 20 applications focus exclusively on women
- Less than half mention the importance of the image subject’s consent
- Over half not only undress the image subject but put them in a sexual position
We identify key stakeholders who can demonetize the ecosystem including:
- Platforms & networks that host service advertisements & referral links
- Payment processors (including Visa, Paypal, etc.)
- Repositories of models & code used to power functionality
Authors: Cassidy Gibson, Daniel Olszewski, Natalie Grace Brigham,
Anna Crowder, Kevin R. B. Butler, Patrick Traynor, Elissa M. Redmiles, Tadayoshi Kohno
Awards:
🏆 2025 Internet Defense Prize Runner-Up
🏆 2025 CSAW Applied Research Competition Best Paper in Social Impact
🏆 2025 USENIX Security Distinguished Paper Honorable Mention
Press Coverage:
📰 ;login: Magazine The Tools and Tolls of AI Nudification...
Building Safe Models from the Ground Up

Shaping Social Norms with Deterrence Messaging
Our research finds that 90%+ of Americans think creating & sharing SNCII is unacceptable.
But barely 50% think viewing is unacceptable.
We’re using principles from psychology & persuasion to craft effective deterrence messages intelligently targeted to perpetrator’s underlying motivations using computational approaches. Our deterrence research focuses on deterring SNCII creation & viewing. We will evaluate our messages in the field in collaboration with large platform partners.
Research team: Dr. Asia Eaton, Dr. Amy Hasinoff, Nina Dours
Rigorous Measurement of Identifiability
The rapid advancement of computer vision techniques for generating and modifying images of people has created a significant threat to peoples' safety online: the generation of synthetic imagery that depicts a recognizable person in harmful and abusive contexts. The threat of AI-generated likenesses has led to policies against the creation of ``likenesses'' of real people, in explicit and non-explicit contexts. The TAKE IT DOWN Act prohibits the distribution of AI-generated non-consensual intimate imagery, YouTube implemented a ``likeness detection'' intended to allow creators take down unauthorized AI-generated likenesses of themselves, Sora has implemented “Cameos” intended to allow people to control the use of their likenesses, and CivitAI, a platform for sharing Text2Image models, banned models trained to produce ``likeness content''.
Yet, what is the most appropriate set of metrics to assess when a synthetic image depicts someone’s likeness? Our research benchmarks different computational and human perception approaches to measuring the identifiability of a likeness against the highest standards of scientific evidence in order to recommend best in class metrics that platforms can use to mitigate the creation of synthetic non-consensual intimate imagery.
Forecasting New Attacks
